mysql出现了waiting for global read lock 全局事务等待问题排查
问题发现
在一个普通的日子里,寒澈在操作他负责的一个内部系统的时候,突然发现一个修改状态的操作不能操作了。 查看服务器日志,发现数据库连接超时了: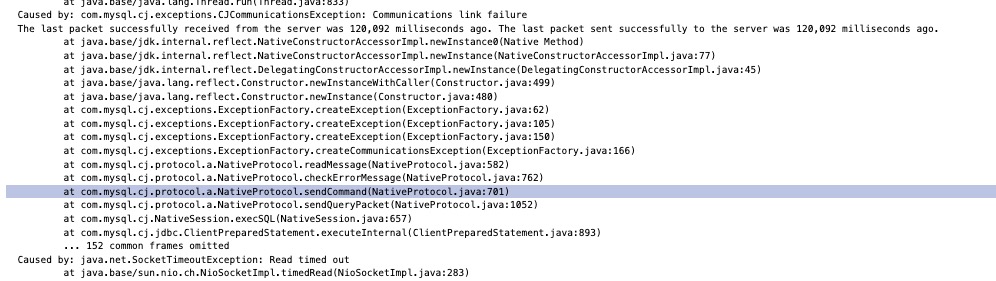
第一反应是数据库挂了,导致数据库连不上了。
可是,神奇的是,接下来发现数据库的查询功能还能用,但是所有的状态修改类的写操作都不能用了。 这下知道遇到麻烦了,肯定是mysql数据库的产生锁了,把所有的写操作阻塞了。
按照现在的这个情况,mysql读没有问题,写被阻塞,出问题的锁肯定是读锁(共享锁),而且还是全局性质的,因为所有的写都被影响了。
问题定位
按照上面的思路去数据库里执行一下SHOW ENGINE INNODB STATUS, 查看一下数据库的状态。 结果如下:
1 | |
发现了大量的如上的事务在积压,没有执行。 与预期一致,就是某个锁导致事务阻塞了。
注意这里不会是死锁问题,因为死锁是锁冲突,mysql会自动解决的,不会导致事务长时间阻塞。
查询一下mysql的执行进程,看看情况:
1 | |
发现了如下场景
由此我们知道:
- 确实发生了一个全局性的读锁
waiting for global read lock导致了后续写操作的进行。 后面的事务都在等待这个读锁的释放。 - 情况比我们想象的严重,这个读锁不仅影响了我们自己的实例,还把整个mysql下所有的库实例都影响了。
- 问题的原因也发现了,就是有一个binlog dump后没有结束导致的。也就是那个耗时最久的进程。
问题解决
既然发现了这个锁产生的原因,直接把这个进程kill掉就可以了
1 | |
binlog的进程杀掉后,后面阻塞的任务果然都没了。
记录一下排查问题过程中常用的sql
1 | |
问题避免
发现问题,解决问题,避免问题才是我们排查问题最终要的目的。
我们这个问题是flink cdc 数据的时候导致的,后续的解决办法很简单:
第一: 以后flink 不要cdc主库了,避免对业务产生影响。
第二:flink cdc 一定要做好异常拦截处理,我们这就是因为异常导致fink退出了,无法释放锁
第三:如果可以的话,尽量使用flink的无锁cdc版本
关于这个global read lock是怎么产生的
当mysql在dump整个数据库的时候,会对数据库执行一个FLUSH TABLES WITH READ LOCK命令来加锁,这个命令会停止对所有表的写操作,并允许读操作继续。
等备份完成,会使用UNLOCK TABLES来解锁,